
티스토리 뷰
공부하면서 필요하다고 생각한 것을 정리하는 것이라 완벽하지는 않지만 참고하셔서 도움이 된다면 기쁠 것 같습니다. 내용에 의문이 드는 부분이 있다면 더 좋은 자료를 같이 보시기를 권장합니다. 틀린 내용이 있거나 내용에 대한 제안이 있다면 댓글로 남겨주시면 감사하겠습니다. 본 글은 개선을 위해서 수정될 수 있습니다.
파이썬으로 머신러닝을 공부중인데, 2차원행렬을 사용시, row col이 혼동되고 인덱싱, 슬라이싱이 나오면 코드가 바로바로 안 읽어지니 비효율적이고 자꾸 멍때리게 되어서, 정리할겸 이 글을 작성한다. 2차원행렬을 익숙하게 활용하는데 필요한 기본개념과 활용법에 초점을 두고 정리한 내용이다.
다차원 배열이 정의되는 방식은 라이브러리마다 조금씩 다르다.
- 파이썬에 기본 내장된
list를 중첩하여 다차원 배열을 만들 수 있다. 그냥 데이터의 나열에 가깝다. Numpy넘파이 :ndarray는 Matrix연산(행렬)을 위한 데이터이다. 차원의 정의가 있는 데이터이다Pandas판다스 :DataFrame은 의미있는 데이터셋을 주로 가지고 있으며col,index를 좀 더 적극적으로 정의하고 있다.
본 글에서는 numpy를 기준으로 설명하는데 , pandas에서도 거의 똑같이 적용된다.pandas에서는 데이터에 header 옵션이 있는점, 데이터프레임을 만들때 딕셔너리로 column별로 정의할 수 있는점. 그외 옵션이 더 있는데 기본으로 사용할 시에는 이 글의 내용이 적용 된다.
Row & Col
넘파이 어레이에서는 2차원 데이터를 아래처럼 정의할수 있다.
np_a = np.array( [[1,2],[3,4],[5,6]] )자 이것을 출력하면 아래처럼 나온다.
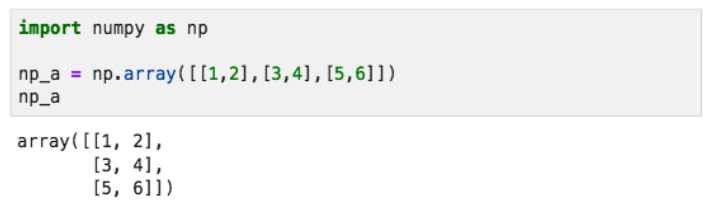
가장 바깥의 ,로 구분되는 각 덩어리를 행 단위로 한줄 한줄 나눠서 쌓는다.
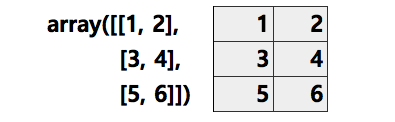
표로 해석할때는 보이는대로 row, col을 정하면 된다.
가로 줄은 행(row)이고, 세로로 나열된 것은 열(col)이다.
아래 예시는 3행, 2열의 데이터이다.
Shape
그러면 위 넘파이어레이의 shape는 ?
- 행과 열의 갯수로 다차원행렬의 모양을 표현할 수 있는데 이것을
shape라고 부른다 - 행의 갯수를 먼저 쓰고, 열의 갯수를 써준다.
- Shape = (행의 수 , 열의 수)
- Shape = (rows, cols)
인덱싱 Indexing
위에서 썼던 numpy array를 계속 사용한다.

Q np_a[0,1] 은 어떤값을 가리키는가?

(Numpy Array의 인덱싱) row부터 카운트하고, 그다음 col을 카운트한다.
나는 이게 너무 헷갈려서 보드게임 말을 움직이는 것을 연상하는 방법을 만들었다.
(이렇게 까지 해야 되나? 생각이 든다면 패스해도 좋다.)
첫번째 숫자만큼 밑으로 먼저 가고 그다음 숫자만큼 오른쪽으로 이동한다.
아래 예시는 이 방식으로 A[0 ,1 ]을 찾는 과정, A[2 ,1]을 찾는과정을 보여준다.
예제
아래와 같이 데이터가 저장된 넘파이 array A가 있다고 하자

(1) A[ 0 ,1 ]의 값은 ?
(2) A[ 2 ,1 ]의 값은 ?

(1) 2 (2) 6
슬라이싱
슬라이싱은 자른다는 뜻이다. 데이터의 일부만 잘라서 가져온다고 생각하면 될것 같다.
데이터를 인덱싱 할때, 특정 범위를 한꺼번에 지정하는 식으로 데이터를 한꺼번에 선택할 수가 있다.
엑셀에서 표의 일부분을 선택한 다음 복사해서 다른 곳에서 사용하려는 상황을 상상해보자.

범위를 표현하는 방법
- 기호
:를 활용해서 범위를 나타낼 수 있다. - 예를 들면,
[0:5]는 0이상 5미만의 값을 나타낸다. 즉a[0:5]``라고 쓰면 a[0],a[1],a[2],a[3],a[4]를 한꺼번에 부르는 효과를 갖는다. - 파이썬
리스트/넘파이 어레이/판다스 데이터 프레임모두 이런 식으로 데이터 슬라이싱 가능하다.
범위를 활용한 인덱싱
범위라 함은 여러 줄을 한꺼번에 선택하는 것을 의미한다. a부터 b까지~처럼 지정할 수 있다.
인덱싱할 때에 [rows, cols] 의 순서로 위치를 표시할 수 있었다.
같은 순서로 rows또는 cols에 :기호를 활용한 범위를 적어주면 된다.
- [ rows, cols ]꼴로 표현 - [, ] 사이에 row의 범위를 먼저 쓰고, col의 범위를 써준다.
- 선택 범위가 1칸이면 범위가 아니므로 colon 기호를 쓰지 않는다. 인덱싱 할때처럼 쓰면 된다.
- a부터 b까지는 a:b로 표시
- a부터 끝까지는 a: 로 표시, 처음부터 b까지는 :b 로 표시
- 데이터 전체를 다 선택하려면 콜론(:) 하나만 표시
슬라이싱 후의 Shape
기본적으로 슬라이싱 전의 모양이 유지된다.
행을 슬라이싱 한게 행이되고 열을 슬라이싱 했으면 열이된다.
주의할 점
슬라이싱 후의 결과가 2차원이라면 행, 열이 유지되지만, 1차원으로 바뀌었다면 데이터가 행인지 열인지의 구분이 없어진다.
1차원인 데이터를 판다스에서는 시퀀스 데이터라고 한다.
(1차원: 시리즈, 2차원: 데이터프레임, 3차원: 판넬 데이타)
More about 판다스
판다스 데이터는 DataFrame이라고 부른다.Column과 Index, Data로 이루어져있다
판다스 자료는 loc, iloc, ix를 통해 행데이터를 추출할수 있다.range를 통해 좀더 복잡한 다중 선택을 할수 있다.
이런 부분들을 다 다루지는 못 했는데, 나중에 시간이 되면 이어서 쓰도록 하겠다.
'Programming > Python' 카테고리의 다른 글
| 유튜브 채널의 쇼츠 영상만 일괄 다운받기(python) (2) | 2023.02.14 |
|---|---|
| (scikit learn 경고문)The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. (0) | 2019.08.12 |
| Virtualenv사용 방법 메모 (0) | 2019.05.24 |
| pip update하는 방법 (0) | 2019.04.27 |